Catch bad data
before your customers do.
Field-level evals for LLM-powered web extraction pipelines. Compare page-extracted outputs against trusted labels, catch schema-valid JSON that is still wrong, and see which fields broke before they ship.
Plugs into your existing stack.
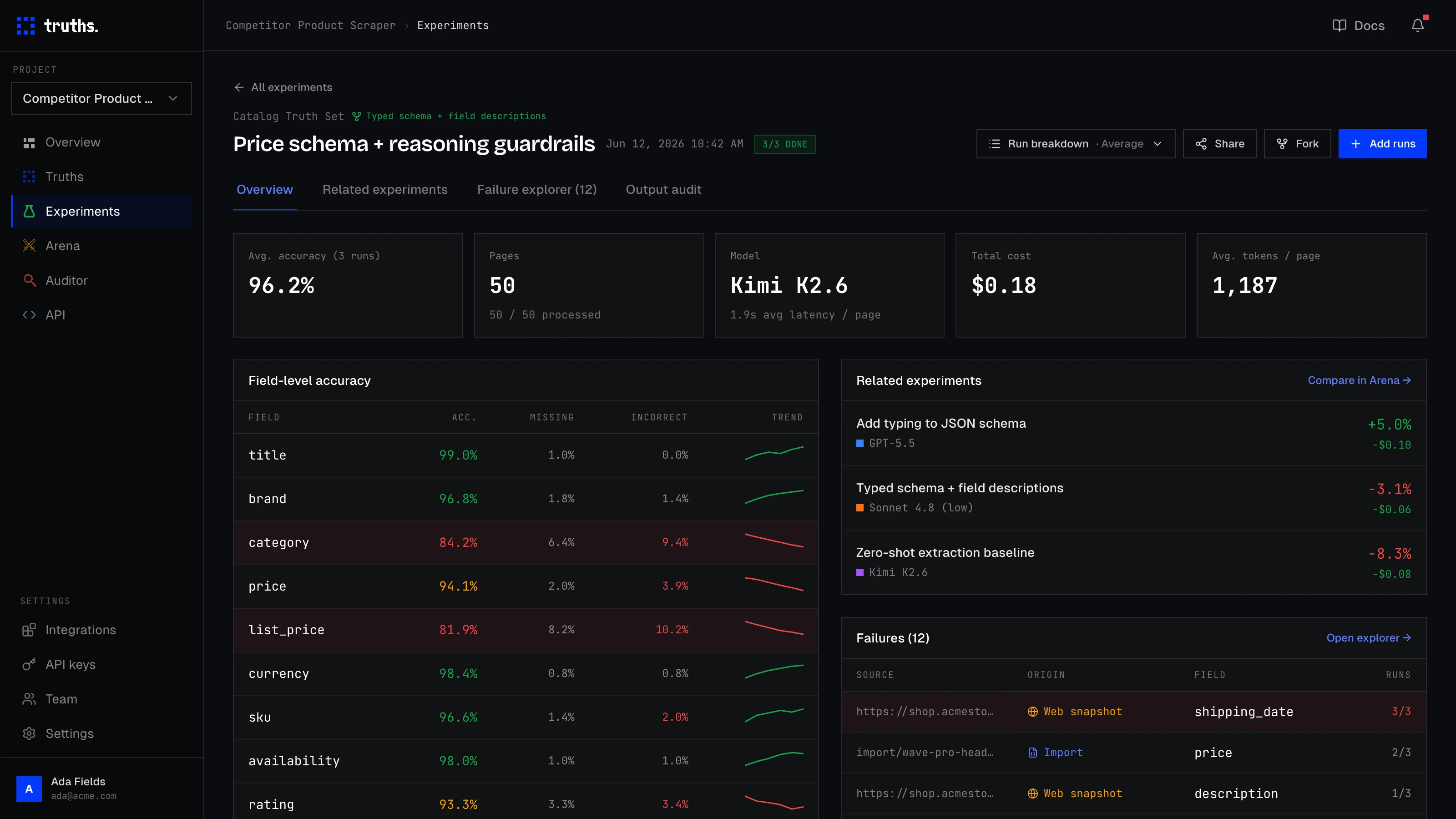
Run field-level experiments on every pipeline you ship.
Experiments give each critical field its own grader. Choose from LLM graders, fuzzy string matching, numeric ranges, and more. Find regressions before they flow downstream.

Use cases
Build ground truth datasets with ease.
Create ground datasets from imported HTML or captured web snapshots. Add truths by pairing them with golden JSON, or label values directly on the page with the Visual Labeler.

Renovated Leslieville semi on a walkable stretch of Queen East.
Pick the best accuracy per dollar.
Run models, prompts, and pipelines against the same Truth Set so you can cut costs, improve accuracy, and ship with confidence.
| Prompt | Acc. | $/1K | Acc/$ |
|---|---|---|---|
| Baseline | 88% | $1.95 | 45.1 |
| + Few-shot | 93% | $2.10 | 44.3 |
| + Schema-anchored | 97% | $1.95 | 49.7 |
Winner: Haiku 4.5 (tuned) — 97% accuracy at $1.95 / 1K, beating GPT-5.5 (96% @ $7.25) for ~4× less. More expensive ≠ more accurate.
Catch cost spikes and schema drift in production.
Just a few lines of code stream live telemetry — cost per page, schema adherence, and null rates — then promote the worst offenders into Truth Sets.
Production telemetry by URL pattern
| URL pattern | Pages | Cost | Trend | Schema |
|---|---|---|---|---|
| /products/* | 9,841 | $0.021/page | 99.1% | |
| /search/* | 5,212 | $0.088/page | 92.4% | |
| /reviews/* | 2,633 | $0.047/page | 96.8% | |
| /category/* | 3,094 | $0.019/page | 99.4% |
Promote /search?q=running+shoe to 'Catalog' Truth Set?
Own your infra. Use it anywhere.
Drop Truths.dev into CI, batch jobs, or agent loops. Define what correct looks like once, then gate every deploy on field accuracy.
# score one output against ground truth
result = truths.evaluate(
truth_set_id="ts_trailrunner_pages",
output=extractor.run(url),
)
# gate the deploy on field accuracy
assert result.verdict != "failed"
# compare pipelines, monitor production
truths.arena.compare(["exp_prompt_v6", "exp_prompt_v7"])
truths.auditor.events.create(result.telemetry)Why teams choose Truths.dev
LLM eval platforms are built for conversations. Scraping tools are built for access. Truths.dev is built for the messy middle: proving extracted web data is correct, cheap enough, and schema-valid in production.
| Generic LLM evals | Scraping monitors | In-house scripts | Truths.dev | |
|---|---|---|---|---|
| Field-level JSON accuracy | Partial | — | Manual | ✓ |
| Missing vs incorrect failure types | — | — | Hard | ✓ |
| Visual DOM-to-JSON debugging | — | — | — | ✓ |
| Model / prompt / pipeline Arena | Partial | — | Manual | Arena |
| Token cost per page in production | Partial | — | Manual | ✓ |
| Production schema adherence | — | Partial | Manual | ✓ |
| Promote failures into Truths | — | — | — | ✓ |
Common questions
Quick answers about Truth Sets, evals, Arena, Auditor, and how Truths fits your extraction stack.
What is Truths.dev, and how is it different from schema validation?
Truths.dev audits LLM-powered web extraction by scoring extracted JSON against labeled correct values. Schema validation only checks shape and types; Truths scores each field, handles exact numbers, fuzzy text, nulls, and custom tolerances, and separates missing and incorrect values.
What is a Truth Set, and what do I need to get started?
A Truth Set is your golden dataset for one extraction task: a schema, labeled examples, and per-field match rules. Import records from your existing pipeline or capture web snapshots, label a handful of pages, then reuse the set across Experiments, Arena, and production audits.
Does Truths.dev replace my scraper, browser agent, or backend?
No. Truths sits downstream of extraction. Keep your current stack for fetching and parsing, whether that is Playwright, Firecrawl, Browser Use, your own backend, or something else. Use the API to trigger eval runs, fetch field-level verdicts, and gate deploys on accuracy thresholds.
How do Experiments and Arena help me improve extraction quality?
Experiments run your extractor against a Truth Set to establish field-level accuracy. Arena compares models, prompts, and pipelines by field accuracy, failure type, cost, and latency, so you can improve the fields that matter instead of chasing aggregate pass/fail.
What does Auditor monitor, and what do you do with that data?
Auditor receives lightweight telemetry from live extraction runs: token usage, cost, model and prompt version, URL pattern, schema health, null rates, latency, retries, and extraction status. Your extraction data stays yours: we only store data for running evals, never sell it, never use it to train models, and support deletion requests. Read the privacy policy for more detail.